Speaker Diarization
Problem to Solve
Speaker Diarization is the process of automatically annotate an audio stream with speakers’ labels. Generally, it is a task of determining the number of speakers who are active and their utterance duration in an audio file.
Speaker Diarization is different compared to two existing popular systems in speech domain which are speaker identification and speech recognition. Speaker Identification serves to determine the speaker identity, answering the question “who is speaking” and the Speech Recognition is to get the words spoken by the speaker, thus extracting “what spoken”. Whereas, speaker diarization solves the problem “who spoke when”. The main goal of speaker diarization system is to extract the speech segments and associate them with the right speaker. The speaker’s labels, derived by diarization process, are relative to the audio recording which means they do not denote the real identity of the speaker. However, they indicate segments that were spoken by the same speaker among the audio file.
Figure 1: Diarization Output

Proposed Solution
We provide a fully unsupervised solution to the speaker diarization task, therefore no need to have a prior knowledge regarding the identity nor the number of speakers in the audio. Our pipeline consists of four steps:
- The first step is a preprocessing step where we select/extract the appropriate acoustic features to work with.
- The second is a Speech Activity Detection block which applies an energy-based measure to classify the speech and silence, and a trained model-based approach to classify speech/non-speech audible sounds. The SAD block eventually outputs the speech-only frames for further diarization. The accuracy of speaker diarization system depends highly on the performance of SAD block.
- The third step is Feature Embedding module in which we employ a deep neural network based on an unsupervised method in order to learn new features from the basic acoustic features.
- The final step is Segmentation and Clustering using Gaussian Mixture Models.
Figure 2: Diarization Process

Technical Approach
After processing an audio file, the system returns an RTTM (Rich Transcription Time Marked) file containing each speaker segments’ and labels with one line per speech turn including the following convention:
SPEAKER {file_name} 1 {start_time} {duration} <NA> <NA> {speaker_name} <NA> <NA>
Figure 3: RTTM Structure

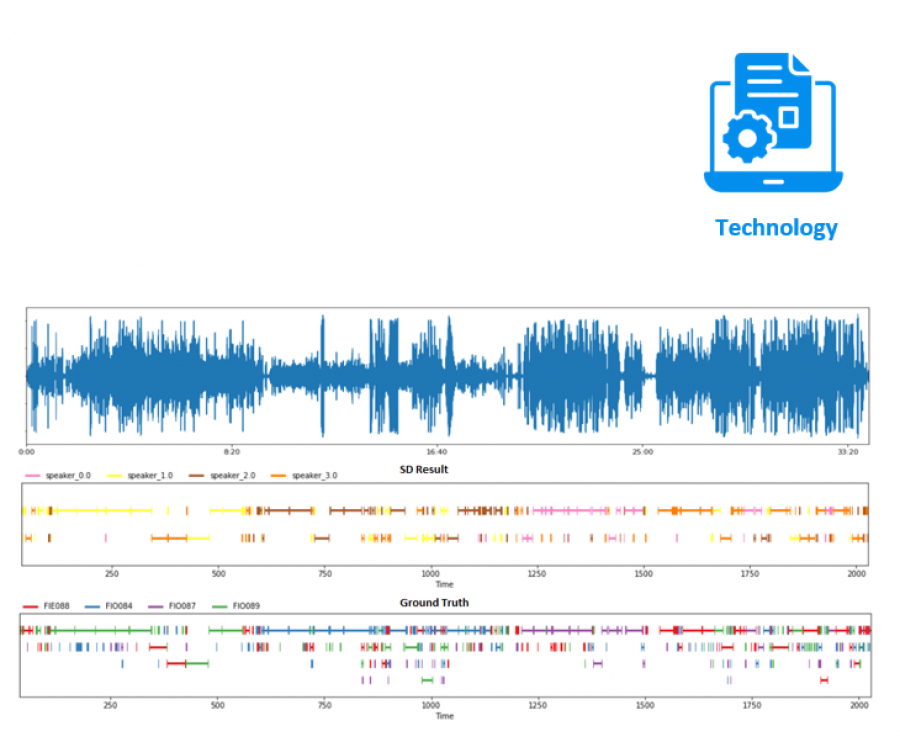
The display of the diarization result gives us the following plot:
Figure 4: Diarization Result

Conclusion and Recommendation
By solving the problem “who spoke when”, speaker diarization has many applications in different scenarios such as:
- Automatic note generation for meetings.
- Speaker verification in presence of multiple speakers.
- Speech to text transcription.
- Video processing.
Speaker Diarization task may encounter many challenges as:
- The number of speakers in the model is unknown.
- There is no prior knowledge about the identity of the people
- Speech length.
- Overlapped speech: many speakers may speak at the same time.
- There may be different audio recording conditions (distance between speakers and microphone).
- Noise ratio: the audio channel can contain music and other non-speech sources beside the speech.
