Table of Contents
Machine Learning Methods for Classification
Supervised Classification via Neural Networks
This use case summarizes findings of a health monitoring study using empirical vibration and temperature data to build a predictive maintenance model. Sensors are placed in four different positions on the housing surface of three running motors at different health stages to study the model performance and its robustness with respect to sensor mounting and various operating conditions. Tens of thousands of data segments were processed and used to extract features and build supervised and unsupervised classification algorithms. A feed forward Neural Network was deployed to classify signals (unseen before by the network) from these 3 motors. Preliminary results look promising with 99.2 % classification accuracy. It is also worth to note the algorithm robustness with respect to sensor mounting.
Data Collection
Vibration and temperature data are collected from rotating machines with the purpose of classifying those machines in one of predefined classes, to wit, “Warning” (scheduled maintenance), “Alarming” (under watch), and “Normal” (no action required). Vibration and temperature sensors are placed on the surface of machine of interest to generate data that will be used to classify machine health and eventually raise warnings when necessary to avoid shutdowns and unscheduled maintenance.
In the experimental setting of this study, 3 motors (numbered 1, 2, and 3) are used. Motor #1 is deemed by the operating personnel to be in a critical condition and may fail at any moment. It generated a distinct loud noise and relatively strong vibration profile and higher than usual surface temperature. Motor # 3 sounded very quiet and smooth thus exhibiting a “normal” behavior. Motor #2 is in between the other 2 motors in terms of noise and vibration strength. Ideally, those motors should run to failure with data being captured at all stages of the motor health for accurate labeling. However, since this is unrealistic and for the purpose of this study, data generated by these 3 motors will be labeled “Warning”, “Alarming”, and “Normal.
Vibration data
A high-quality vibration sensor of up to 48 KhZ sampling rate is attached via a magnet to the housing surface of each one of the 3 running motors. Four different sensor positions are used for data gathering as shown in Figure 1. Varying the sensor position is useful to study the model sensitivity to sensor mounting and operating conditions. The vibration sensor sampling frequency is set at its maximum value of 48 KhZ. Each recording lasted about 90 seconds.

Figure 1. One of the 4 sensor positions used to collect vibration data. In all experiments the sensor is attached to the motor housing surface via a magnet
Temperature data
This preliminary setup did not include a temperature sensor. For the purpose of this study, a temperature sensor response is simulated to allow building realistic machine learning models for classification. Temperature response is simulated as a constant base value plus a random component taken from a set of uniformly distributed pseudo random numbers. Base temperature values for the 3 motors are set respectively at 100, 99, and 98 degrees while temperature spans are [96.6 103.8], [95.6 102.4], and [94.1 101.8] respectively. These overlapping temperature spans seem representative of real sensor measurements given noise and variability of operating conditions.
Feature Extraction
Each vibration track of “T” samples (e.g. T=48,000 x 90=4,320,000 samples) is divided into non overlapping segments of equal length (i.e. S=1024 samples or 21.3 milliseconds per segment) to generate features in the time-frequency domain.
Feature definition
Preliminary features selected for this study are defined as follows:
1. Time domain energy measure of the vibration signal. It is estimated as the root mean squared value of the vibration time series in the segment of interest (i.e. "![]() "):
"):
![]() (1)
(1)
Where V(k) is the vibration amplitude at time sample “k”, “S” is the segment length in samples (i.e. 1024), and “m” is the segment rank varying from 0 (first segment) to the rounded value (T/S-1) (last segment), with T being the total track length (in samples).
Since “S” is a given constant, the feature notation can be simplified as follows:
![]() (2)
(2)
With ![]() being the vibration time series at segment # m, that is:
being the vibration time series at segment # m, that is:
![]() (3)
(3)
Studying the effect of segment length “S” and its overlap with neighboring segments is an interesting factor that will be addressed in future studies. This feature (i.e. time domain energy) is useful in classification as it provides a general indication of the machine health: the lower this feature value is, the healthier the machine is. Figure 2 shows an example of this feature values across the 3 studied motors
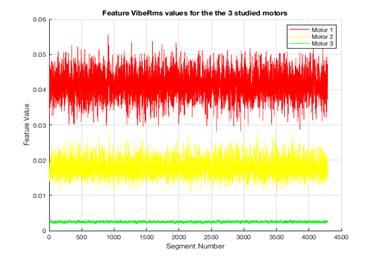
Figure 2. ![]() feature for the 3 motors
feature for the 3 motors
2. Frequency domain energy measure in the 8 bins corresponding to the frequency band [f(10), f(18)]=[422 797] HZ. This feature is driven by the frequency responses of the three motors since most of the energy for motors # 1 and 2 was concentrated in the area [400-800] HZ; it is calculated as follows:
![]() (4)
(4)
Where ![]() represents the Fourier transform operator. Figure 3 shows this feature variation across the 3 studied motors
represents the Fourier transform operator. Figure 3 shows this feature variation across the 3 studied motors
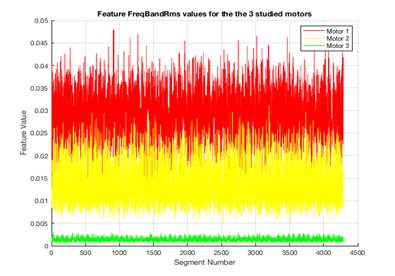
Figure 3.![]() feature for the 3 motors: according to this feature, motor # 3 (“Normal”) is separated from the other 2 motors
feature for the 3 motors: according to this feature, motor # 3 (“Normal”) is separated from the other 2 motors
3. Peak energy value in the frequency domain. It is computed as follows:
![]() (5)
(5)
This feature exhibited robustness across sensor positions as it will be apparent later. Figure 4 shows the feature variation across the 3 studied motors.
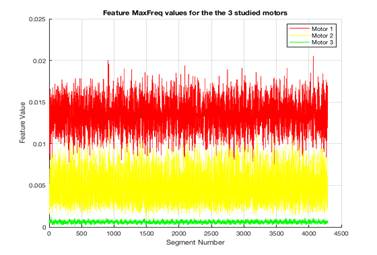
Figure 4.![]() feature for the 3 motors
feature for the 3 motors
4. Simulated temperature
Figure 5 shows variation of the simulated temperature response across the 3 studied motors.
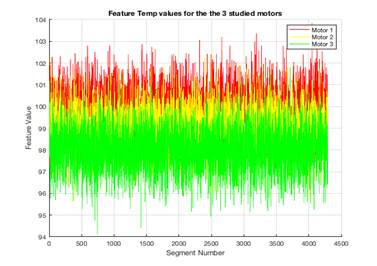
Figure 5. Simulated temperature response across the 3 studied motors
Feature across all data sets
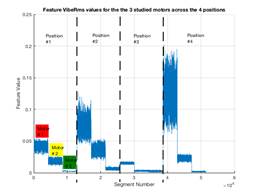
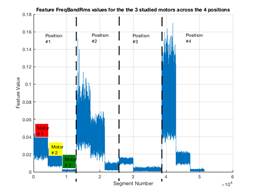
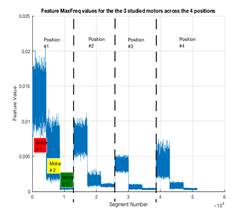
Figure 6 shows variations of the 4 features defined in the previous section based on all data captured from the 3 different motors at the 4 sensor positions with a total of 51,456 data segments based on a segment length of 1024 samples. Note that data captured with sensor in position # 3 is least strong; in fact, it coincides with the least audible vibration sound that was noticed during data gathering. Note also, that feature # 3 (i.e. Peak energy value in the frequency domain) is effective (compared to other features) in discriminating between close cases such as motors #2 and #3 in sensor position # 3.
 |
 |
 |
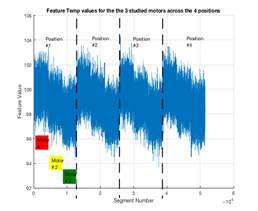 |
Figure 6. Time domain energy (upper left), band-limited frequency domain energy (upper right), peak frequency domain energy (lower left), and simulated temperature (lower right) computed over segments of time for the 3 studied motors across the 4 sensor positions. A data set for each feature is comprised of 4 segments juxtaposed horizontally corresponding to the 4 sensor positions. Each segment is comprised of 3 staircase-like pieces corresponding to the 3 motors.
Feature cross correlation
An important element of feature extraction is to study the correlation between features since it is a measure of their dependency. If the correlation index associated with two features is relatively high then those two features are highly correlated and as such, it is more beneficial to carry only one feature instead of the two in order to reduce over fitting and improve the generalization of models. There are many ways of calculating the correlation coefficients depending on the nature of dependency between the features of interest (e.g. linear versus nonlinear for example). The Pearson correlation method is typically used as it provides a measure of linear dependency between features and is defined as follows:
![]() (6)
(6)
Where N is the number of N scalar observations of both features, ![]() and
and ![]() are the mean and standard deviation of feature A while
are the mean and standard deviation of feature A while ![]() and
and ![]() are the mean and standard deviation of feature B. The correlation coefficient matrix between two features A and B is the matrix of correlation coefficients for each pairwise variable combination.
are the mean and standard deviation of feature B. The correlation coefficient matrix between two features A and B is the matrix of correlation coefficients for each pairwise variable combination.
![]() =
=![]() (7)
(7)
Using equation (6), the correlation coefficient matrix for the 4 studied features across all gathered data is given by the following 4 by 4 matrix:
1.0000 0.9674 0.4086 0.4383
0.9674 1.0000 0.4011 0.4263
0.4086 0.4011 1.0000 0.4335
0.4383 0.4263 0.4335 1.0000
Note that features #1 and #2 (i.e. signal energy in time domain and frequency band [400-800 HZ]) are highly correlated. Features # 3 (peak frequency domain energy) and #4 (Temperature) are, on the other hand, less correlated with the rest of features making them potentially more efficient for model generalization. The selection of final set of features is determined by the performance of the classification algorithm across various operating conditions
Machine Learning Methods for Classification
The predictive modeling problem at hand is a classic case of machine learning. There are many supervised and unsupervised techniques that can be used to classify the three studied motors in their appropriate classes (i.e. “Warning”, “Alarming”, and “Normal”). At this early stage of the project with only a few data tracks collected, two classical algorithms will be tested: unsupervised K-means clustering and supervised feed forward neural networks. As more data will be collected more complex algorithms and architectures will be tried and tested for better classification performance.
Supervised Classification via Neural Networks
A feed forwards neural network with 50-neuron hidden layer and 4 inputs (features) using 70% of the whole data for training (36,019 segments), 15% for validation (7,718 segments), and 15% for testing (7,718 segments) resulted in a successful classification of 99.2% of accuracy as shown by the confusion matrix shown in Figure 7. The confusion matrix also known as error matrix is typically used to visualize the system performance. Each row of the matrix represents the instances in a predicted class, while each column represents the instances in an actual class
In this case, 19 data points of class # 1 (warning) are mistakenly labeled as class # 2 (alarming), 29 points of class #2 (alarming) are mistakenly labeled as class #1 (warning), 5 data points of class #3 (normal) are mistakenly labeled as class # 2 (alarming), and similarly 5 data points of class # 2 (alarming) are labeled as class # 3 (normal). No data point of class # 1 (warning) was misclassified as case #3 (normal) and vice versa. 7,660 (out of 7, 718) or 99.2 % are classified correctly in their appropriate classes.
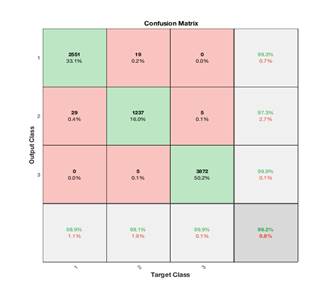
Figure 7. Confusion matrix of a 50-neuron hidden layer Feed Forward Neural Network model shows 99.2% classification accuracy
Conclusion
This report presented an initial machine learning modeling for predictive maintenance based on empirical vibration and temperature data. Vibration sensors are placed in four different positions on the housing surface of three running motors at different health stages to study the model performance and its robustness with respect to sensor mounting and various operating conditions. Gathered data was analyzed to extract features and build supervised and unsupervised classification algorithms. Initial results using feed forward Neural Networks look promising both in terms of robustness to feature selection and sensor position and in terms of algorithm performance with a 99.2 % classification accuracy
In more complex settings such as manufacturing floors and alike with hundreds of machines and millions of signal segments, a more complex structure such as a Deep Learning with recurrent neural networks is more suitable for classification towards an efficient predictive health monitoring approach.
In case of non-labeled data with no a priori knowledge about machine health, there are other methods and techniques to estimate the machine state (e.g. normal, alarm, warning) including clustering methods and other advanced techniques to estimate the remaining useful life of machines. Such a scenario will be addressed in a future case study
