Displaying items by tag: predict
Social Media Analytics for Sales Prediction

Social data analytics has recently gained esteem in predicting the future outcomes of important events like major political elections and box-office movie revenues. Related actions such as tweeting, liking, and commenting can provide valuable insights about consumer’s attention to a product or service. Such an information venue presents an interesting opportunity to harness data from various social media outlets and generate specific predictions for public acceptance and valuation of new products and brands. This new technology based on gauging consumer interest via the analysis of social media content provides a new and vital tool to the sales team to predict sales numbers with a great deal of accuracy.
Predictive Maintenance using Machine Learning
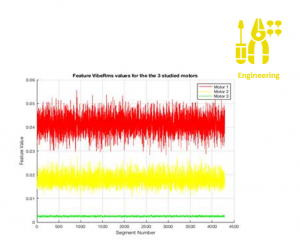
This use case summarizes findings of a health monitoring study using empirical vibration and temperature data to build a predictive maintenance model. Sensors are placed in four different positions on the housing surface of three running motors at different health stages to study the model performance and its robustness with respect to sensor mounting and various operating conditions. Tens of thousands of data segments were processed and used to extract features and build supervised and unsupervised classification algorithms. A feed forward Neural Network was deployed to classify signals (unseen before by the network) from these 3 motors. Preliminary results look promising with 99.2 % classification accuracy. It is also worth to note the algorithm robustness with respect to sensor mounting.
Cancer Detection in Pharmaceutical Industry
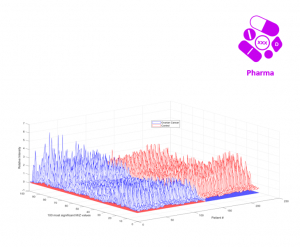
The current business model of pharmaceutical industry where a new drug may take a decade and Billions of dollars to develop is no longer viable in this digital era of big data and cloud computing. Giant IT companies such as Amazon and Google are leveraging their deep pockets and strong AI footprints to lower the entry barrier to this vital sector and render classical models of drug discovery and development obsolete.
Financial Instrument Trend Prediction
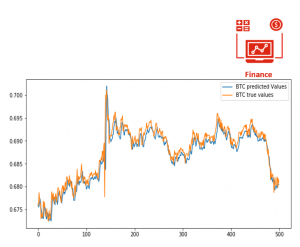
A cryptocurrency is a digital currency that is self-organized, whose value is determined mainly by social consensus. In addition to being decentralized, a cryptocurrency is not backed by any third party or central bank. Essentially, cryptocurrencies are limited entries in a database, not controlled by anyone but by the network itself, which is unchangeable unless specific conditions are fulfilled. All these conditions make cryptocurrency prices unpredictable and constantly fluctuating.